HTTP QUERY (RFC 10008) Explained: Read-Only Requests with Complex Bodies

The Problem: Complex Queries Outgrow GET and POST
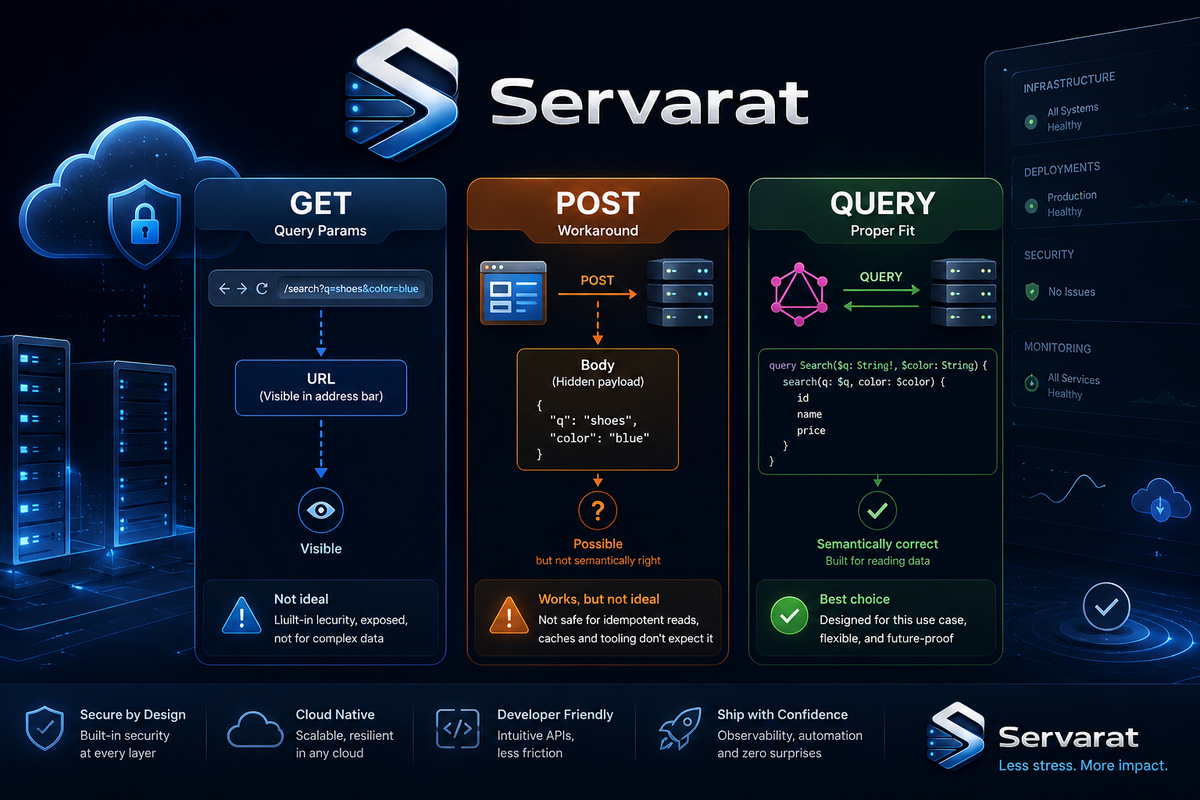
In REST, the HTTP method tells the server your intent. GET fetches, POST creates, PUT updates. This works fine until you need to send a complex read-only query with a structured body.
GET + Query Parameters
Filtering resources with query parameters is simple at first:
GET /api/v1/users?role=admin&status=active&sort=desc
But complex queries break this:
- Deep filtering, nested conditions, arrays, and relational logic turn the URL into garbage
- URL length hits browser and server limits (usually 2-8 KB)
- Special characters and non-ASCII require encoding, bloating the request
- Server logs capture the full query string, which can expose sensitive filters
- Array syntax is implementation-specific and fragile (
?roles[]=adminvs?roles=adminvs?roles=admin&roles=reporter)
POST as a Workaround
The obvious answer is sending a request body with GET—except it's a landmine. The HTTP RFCs don't forbid GET bodies, but they discourage it. In practice:
- Proxies drop the body or reject the request outright
- Corporate firewalls may block it
- Browsers and caches handle it inconsistently
- Corporate proxies behind a different stack may reject it entirely
So people use POST instead. It accepts a body and works everywhere. But POST is defined as non-idempotent and intended for resource creation, not read-only operations.
This breaks:
- Automatic retries: GET is safe and idempotent, so failed requests can be retried without side effects. POST isn't—you risk duplicate creations if a retry happens after the server already processed the first request.
- Middleware understanding: Caches treat GET as safe and cache-eligible. POST isn't cached (for good reason). So POST queries don't benefit from HTTP caching.
- Proxy optimization: Proxies can't understand that a POST is read-only, so they can't optimize or safely retry it.
The Solution: HTTP QUERY
RFC 10008 introduces the QUERY method. Technically, it's simple: it's like GET but accepts a request body, and it's defined as safe and idempotent.
QUERY /api/v1/users
Content-Type: application/json
{
"filters": {
"role": "admin",
"status": "active",
"created_after": "2026-01-01"
},
"sort": {
"field": "created_at",
"direction": "desc"
},
"pagination": {
"limit": 100,
"offset": 0
}
}
Because QUERY is idempotent and safe, middleware and caches can:
- Automatically retry failed requests without risk
- Understand the operation is read-only
- Cache responses (with care—the cache key must include the request body)
- Log and audit without special cases
When to Use QUERY
Use QUERY when:
- Your read query is too complex for query parameters
- You need to send structured data (arrays, nested objects, deeply nested conditions)
- The URL would exceed reasonable limits
- You want automatic retry semantics without side effects
Don't use QUERY when:
- Simple GET query parameters work fine—leave them alone
- Users need to share or bookmark filtered results as URLs (QUERY requests can't be bookmarked)
- Your clients and proxies don't support it yet (see gotchas below)
The Gotchas
Limited Support
QUERY is brand-new. Support is sparse and will be for years. Most clients, proxies, and servers don't recognize it yet. As of June 2026, only a handful of tools (Kreya, some REST clients) have native QUERY support. Your infrastructure may reject it.
Caching Is Harder
GET responses are cached trivially—the URL is the cache key. QUERY responses require incorporating the request body into the cache key. Simple for CDNs that understand RFC 10008; problematic for custom caching layers or basic proxies.
Breakage in Corporate Networks
If your users sit behind corporate proxies or firewalls that whitelist only standard HTTP methods, they'll hit QUERY rejection. This is less of a problem than GET-with-body (since proxies won't silently drop it), but it's still a wall.
Not Shareable
A QUERY request can't be bookmarked or shared as a URL. If your users need to save or send filtered views, QUERY doesn't work—stick with GET query parameters for that use case.
Migration Strategy
If you're considering QUERY for an API:
- Keep simple queries on GET. Don't migrate
?limit=10&offset=0to QUERY just because it exists. - Introduce QUERY alongside POST for new complex endpoints. Let clients opt in. Don't remove POST immediately.
- Test in your stack first. Verify your load balancer, proxy, firewall, and clients support it before deploying.
- Document the shift. Make it clear when QUERY is the right choice and when GET or POST still apply.
⚠️ Introducing QUERY as the primary method for search today is premature—support is too fragmented. Add it as an option, document why it exists, and gradually shift as ecosystem support grows.
Conclusion
HTTP QUERY fills a real gap: read-only requests with complex bodies. For the next few years it'll be a niche tool used only when absolutely necessary and when your stack supports it. Eventually, as clients and proxies catch up, it'll become the default for complex search queries.
For now: GET works for simple filters, POST works as a workaround for complex ones, and QUERY works great—when your entire stack supports it, which isn't most places yet.